RevDecode-CUDA - Project Details
Overview
RevDecode is a Viterbi-based algorithm that provides a polynomial-time solution for traversing graphs and ranking candidate functions in binary malware detection. By modeling binaries as structured, directed layered graphs, RevDecode systematically decodes sequences and identifies the most relevant function mappings.
The initial CPU implementation of RevDecode faces significant performance bottlenecks when processing large-scale data—analyzing thousands of unknown functions with hundreds of candidate mappings can take over 15 minutes, limiting its practical use in malware detection. This thesis presents a CUDA-based, GPU-accelerated implementation of RevDecode that reduces processing time for identical datasets from roughly 16 minutes on a CPU to about 10 seconds on a GPU—achieving nearly a 100× speedup. The implementation employs three kernel approaches—Naive, Segment-Based Estimation, and Fine-Grained—to optimize performance, scalability, and accuracy in processing binary function libraries.
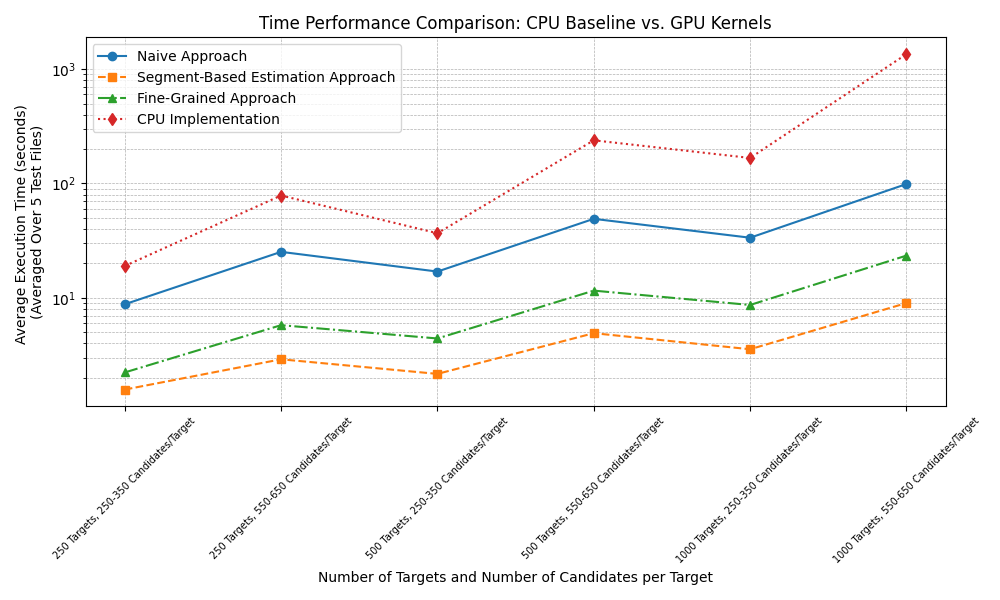
Figure: Time Performance Comparison: CPU vs. GPU.
Architecture Design
CPU Approach
Revdecode models binaries as layered graphs, where each layer represents an unknown function and the nodes within a layer correspond to candidate mappings. Edges between nodes in consecutive layers capture the adjacency relationships that define possible transitions between candidate mappings. The CPU baseline approach processes this graph sequentially, iteratively evaluating the edges between adjacent layers. This results in a time complexity of approximately O(n × m2), where n is the number of layers and m is the average number of candidate mappings per layer.
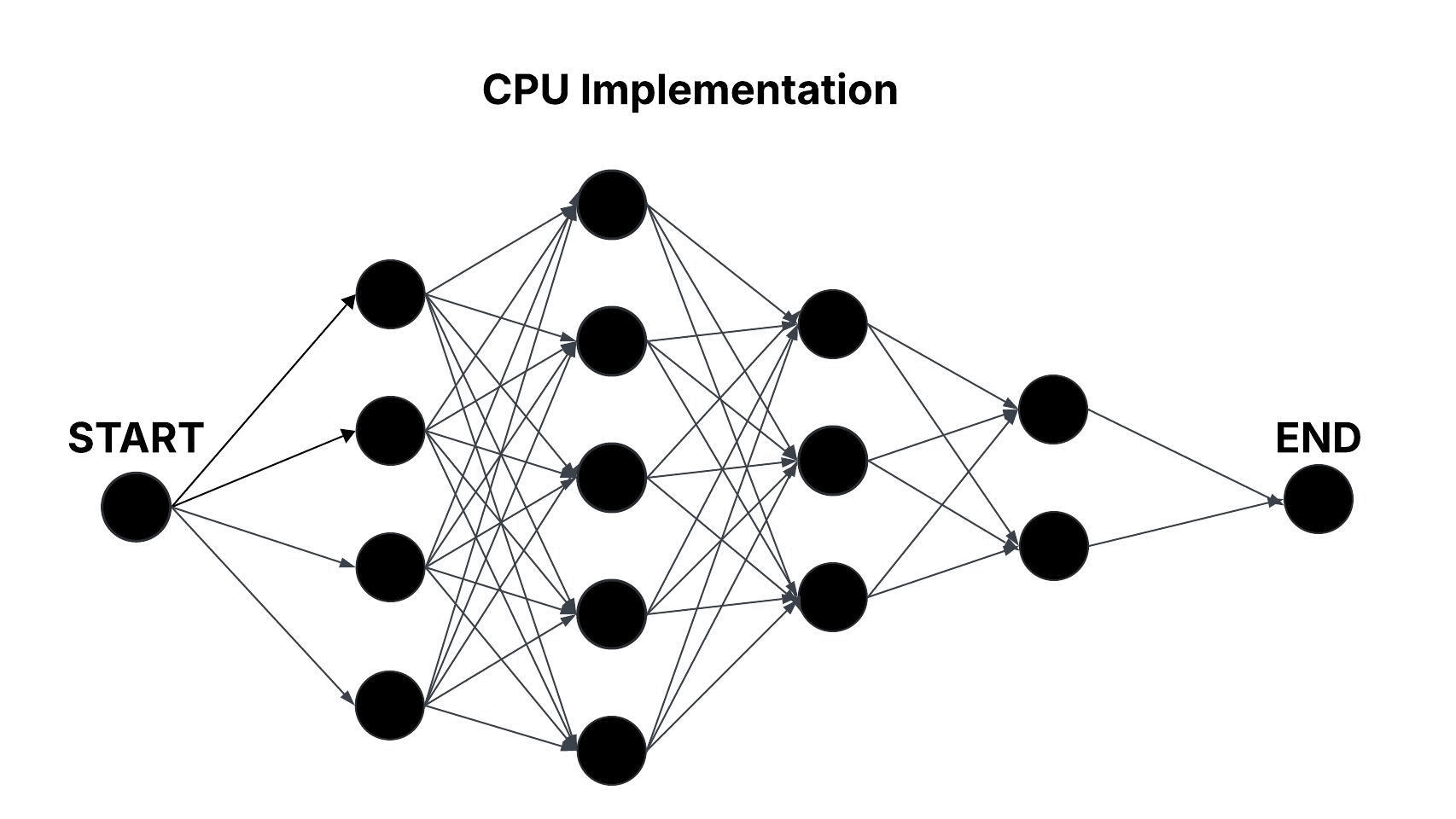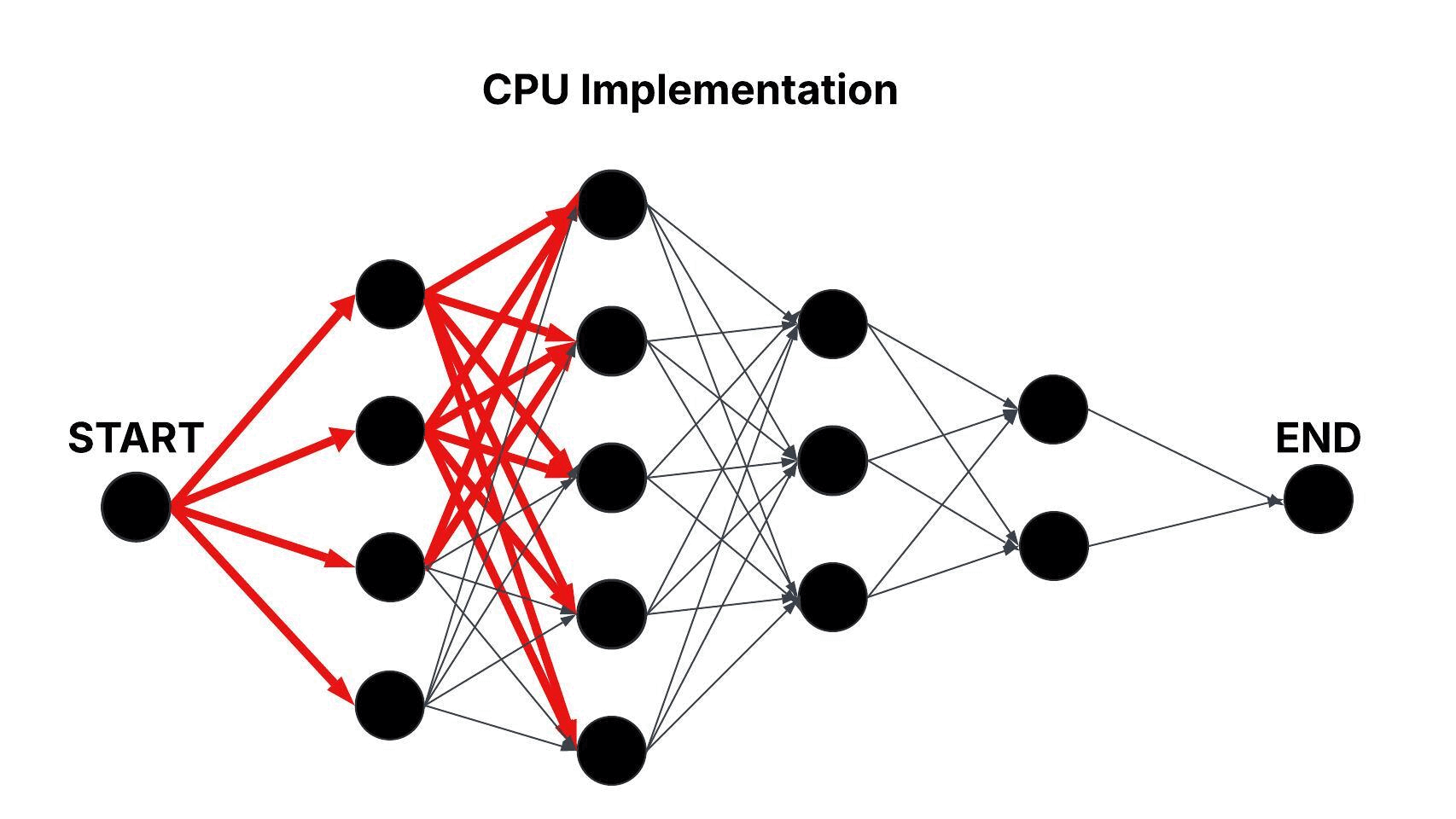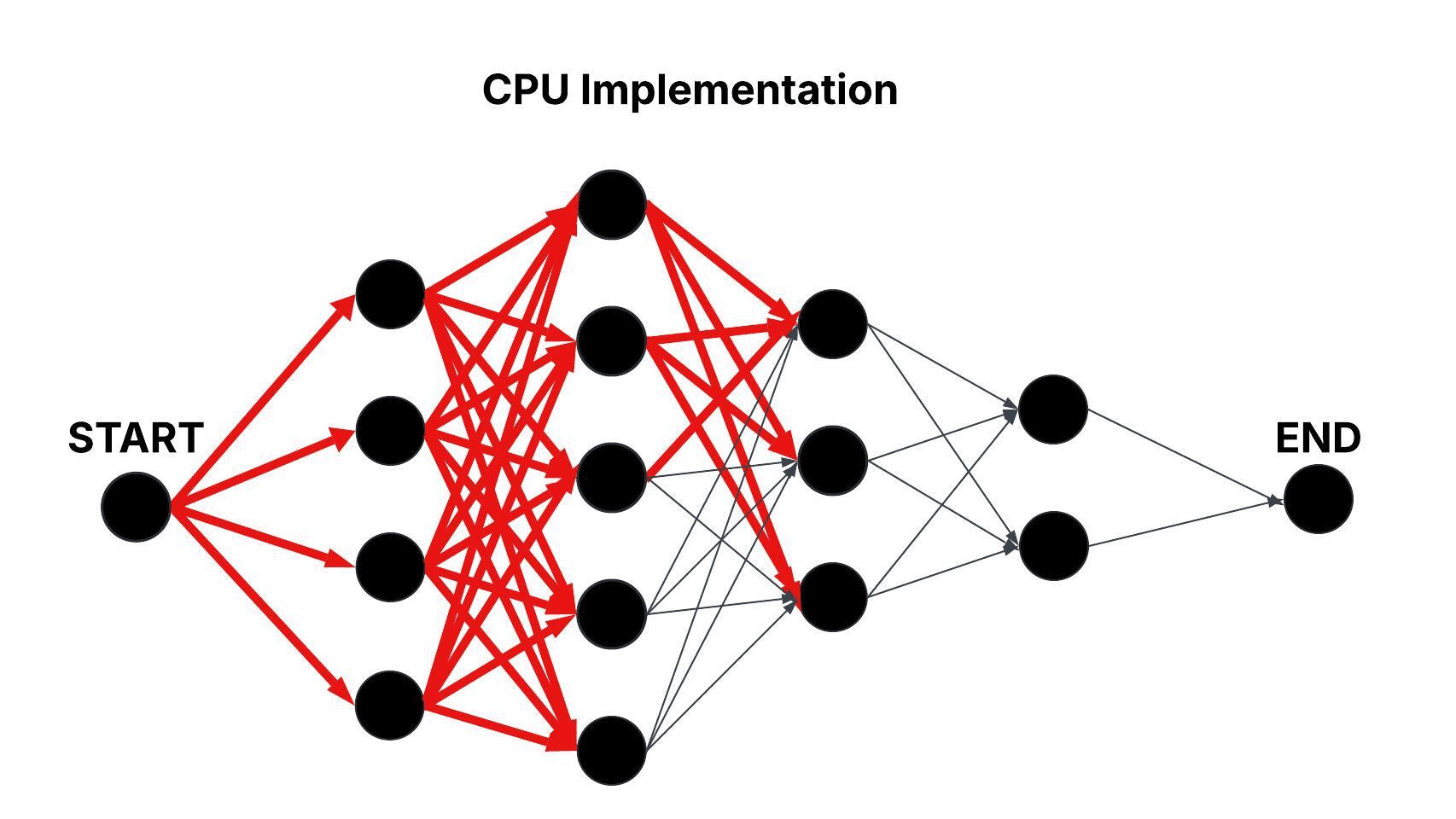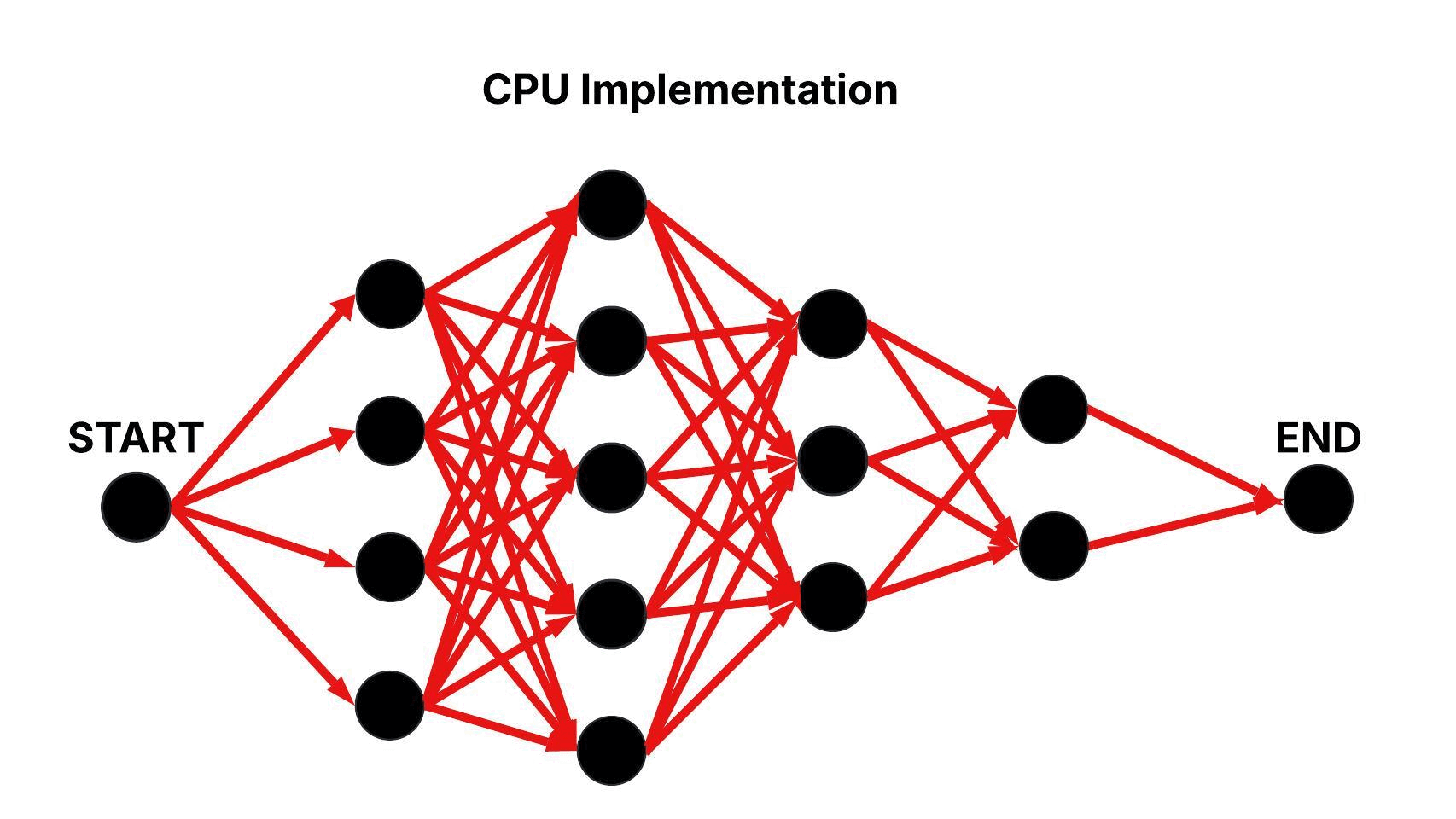
Figure: Sequential Traversal of the Layered Graph in the CPU Baseline Approach.
GPU Naive Approach
In the GPU Naive approach, the same layered graph structure is traversed using parallel execution on the GPU. A single thread block is deployed with m threads, with each thread responsible for processing all edges connecting a node in one layer to every node in its successive layer, iteratively. This parallelization reduces the computational complexity to roughly O(n × m).
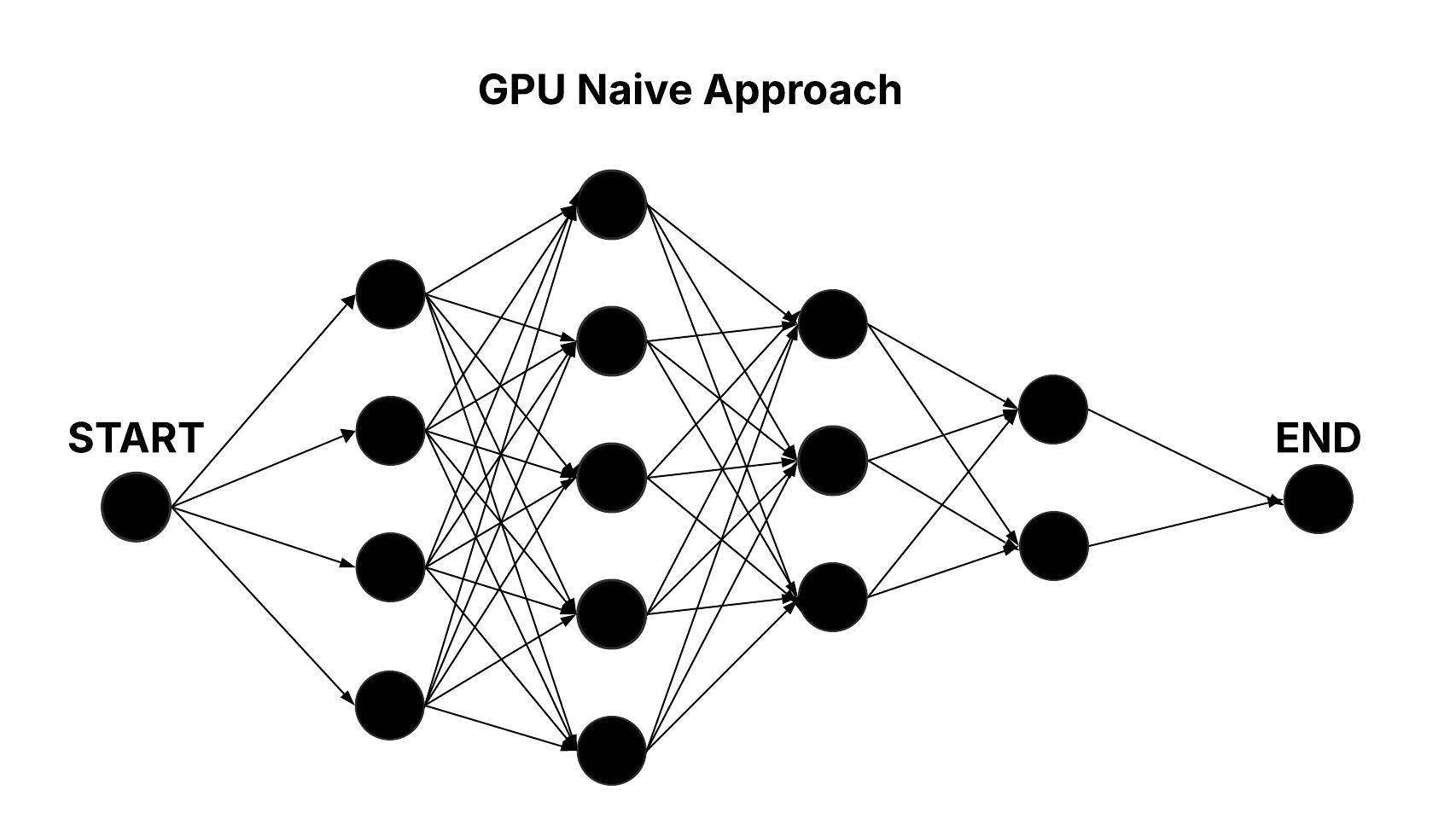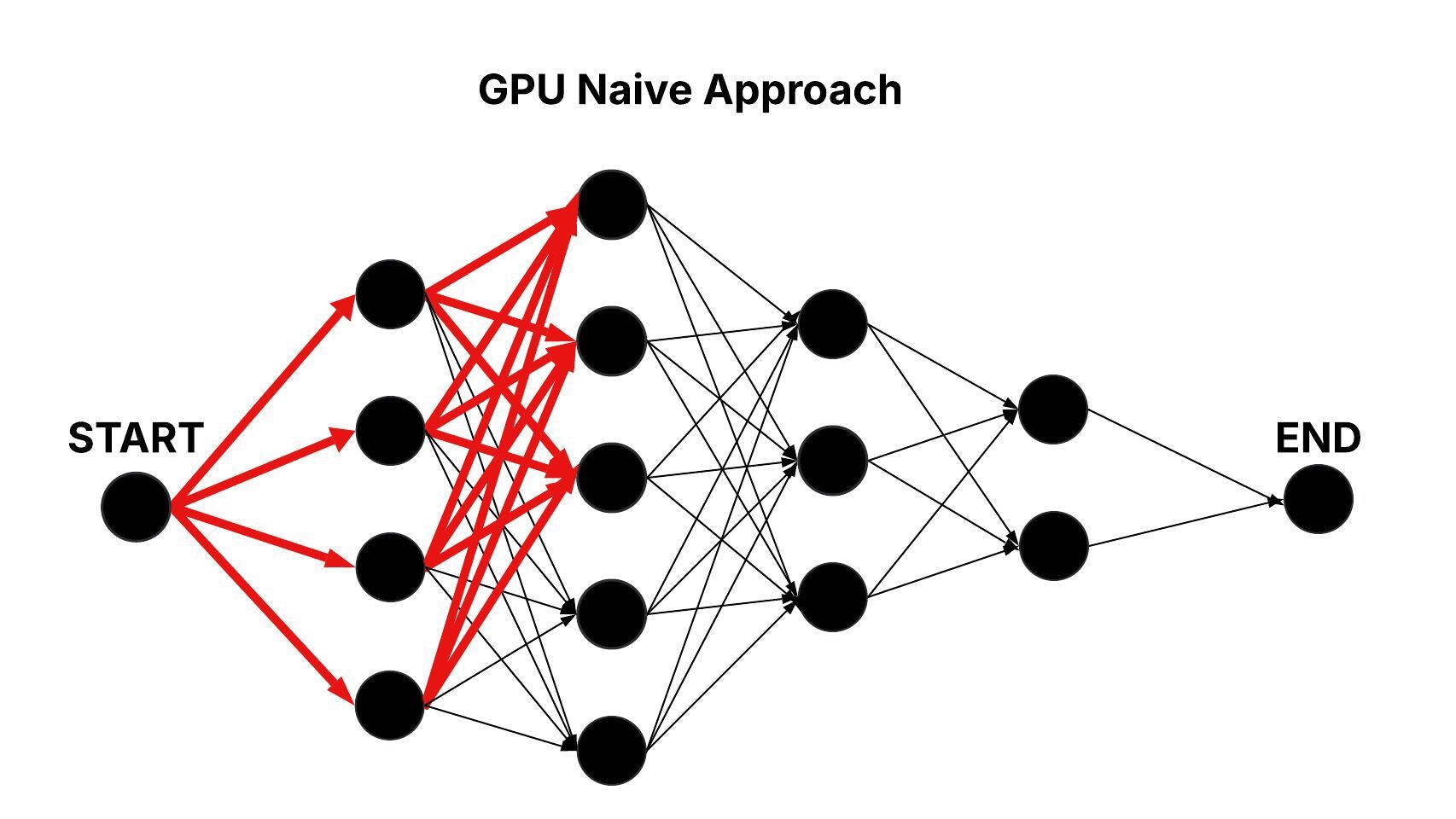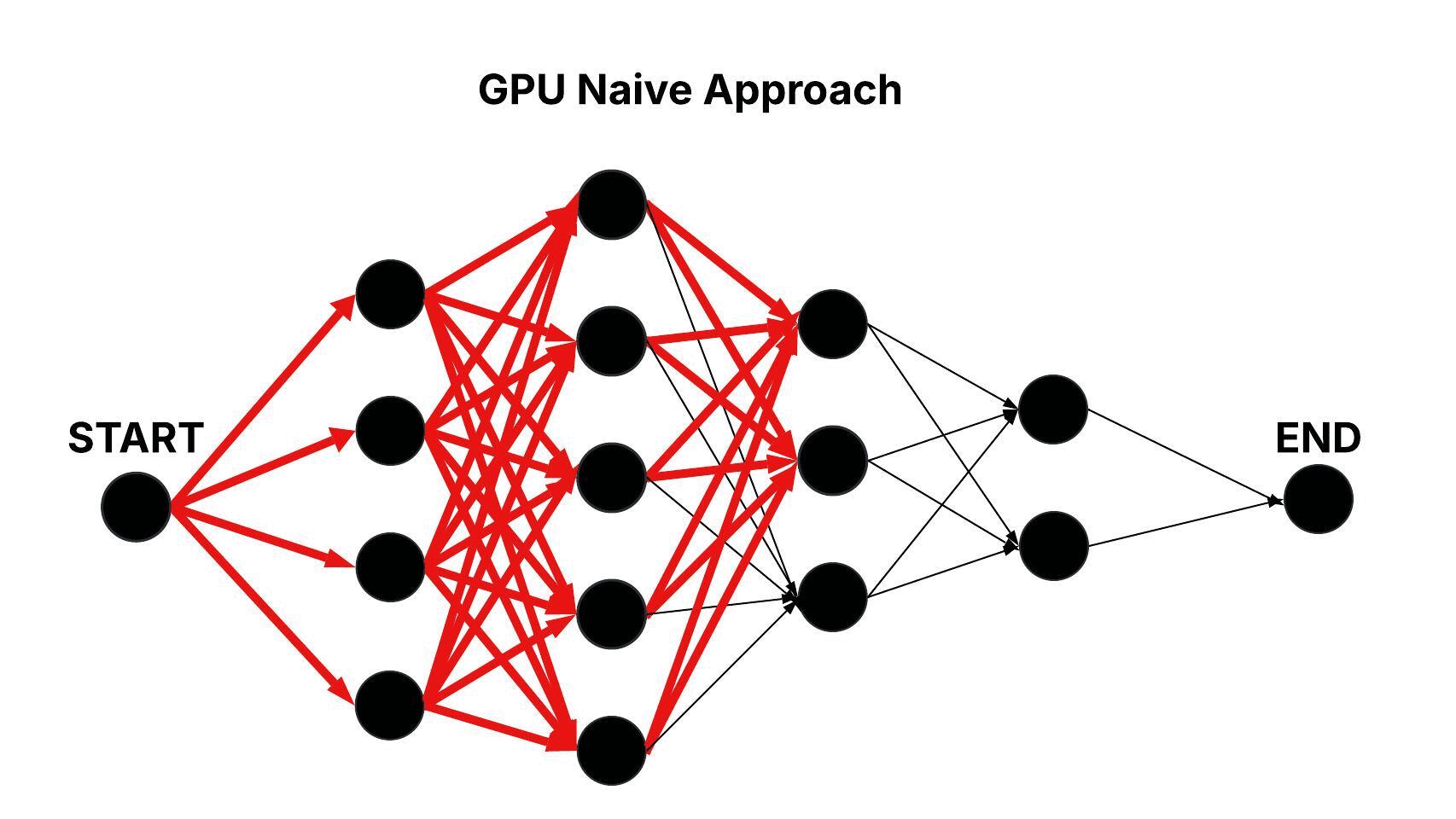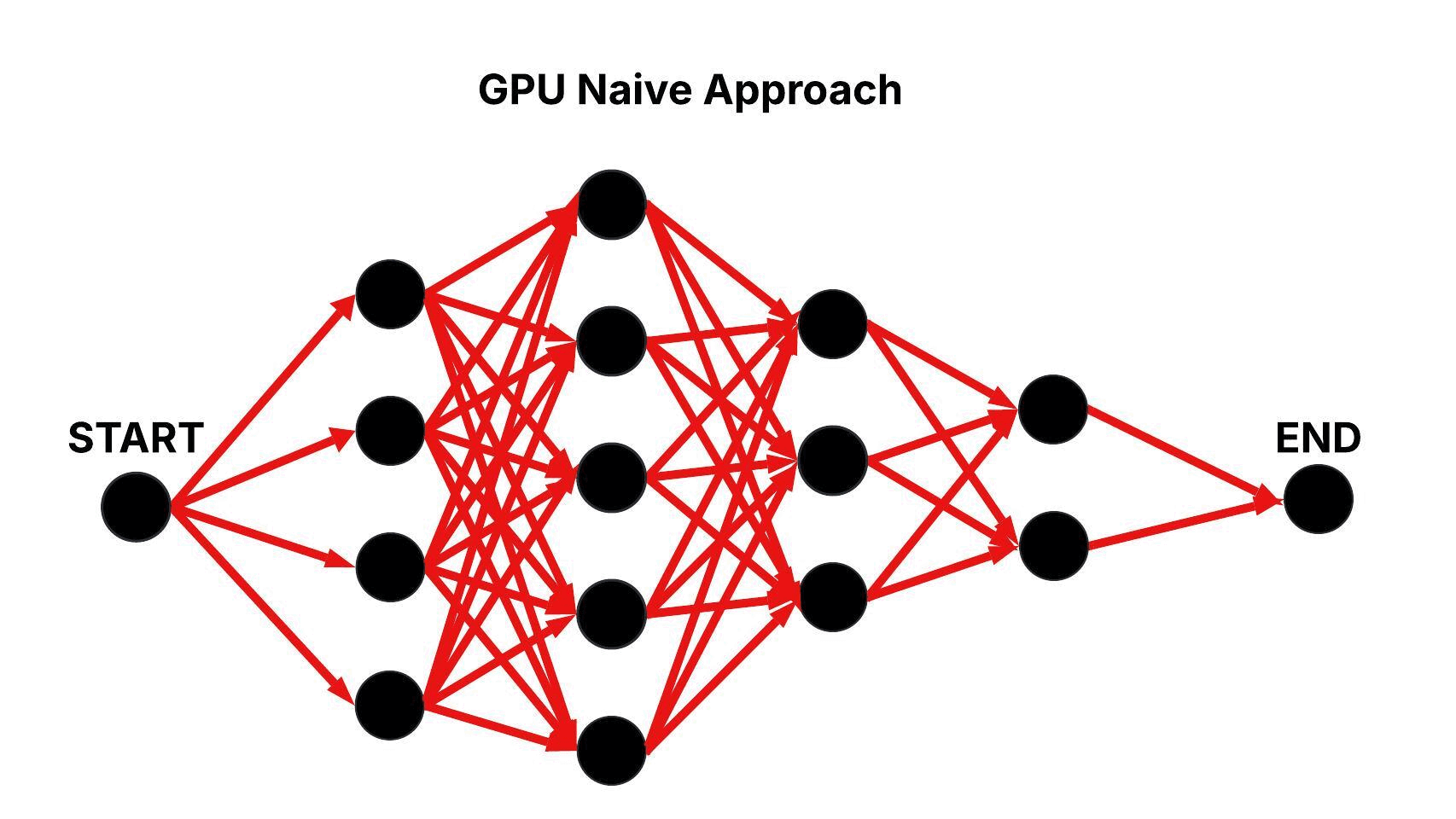
Figure: Parallel Traversal of the Layered Graph in the GPU Naive Approach.
GPU Segment-Based Estimation Approach
The GPU Segment-Based Estimation approach employs an approximation strategy to boost scalability, sacrificing a slight degree of accuracy. The fundamental idea is to divide the layered graph into several segments, with each segment representing a continuous series of consecutive layers. Each segment is processed independently by a dedicated thread block, where threads compute cumulative weights for all edges connecting nodes within that segment—similar to the operations performed in the GPU Naive approach.
Following the initial segment processing, the approach enters a merging stage designed to incorporate dependencies that span segment boundaries. In this stage, adjacent segments are merged iteratively until a single segment remains, yielding the final cumulative weight results. This design ensures that each thread block can handle a manageable subset of the grapgh. Additionally, by partitioning the graph into smaller segments, more thread blocks can be deployed concurrently—each processing fewer layers—which reduces the time complexity to approximately O((n / #deployed thread blocks) x m).
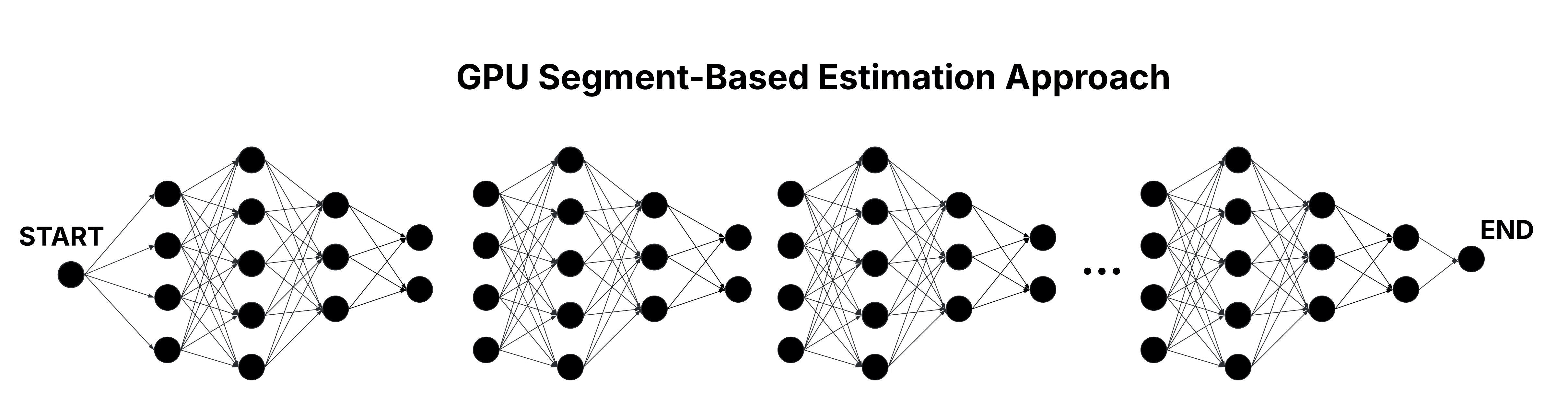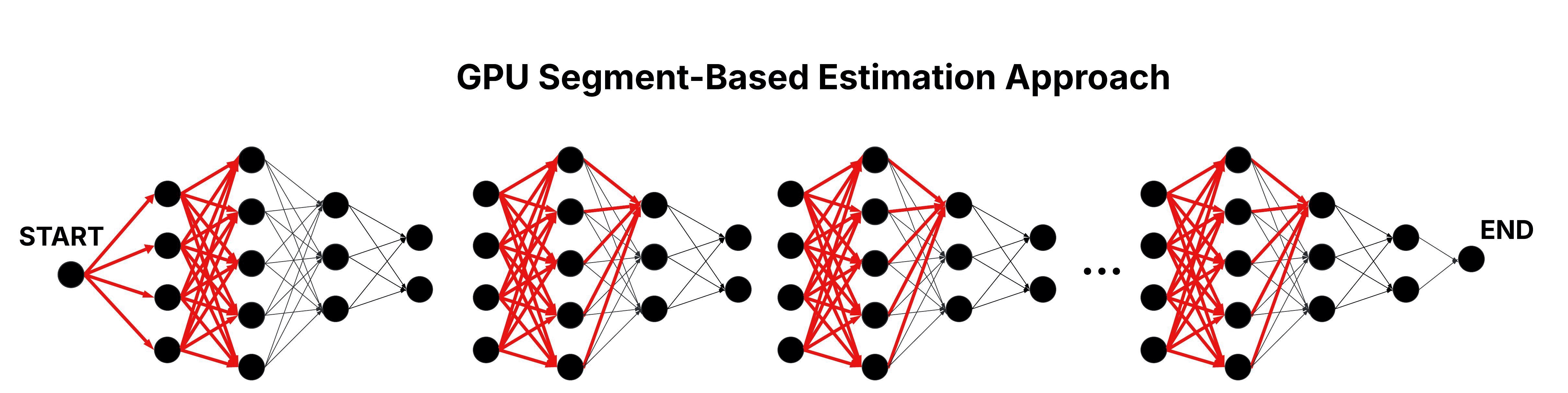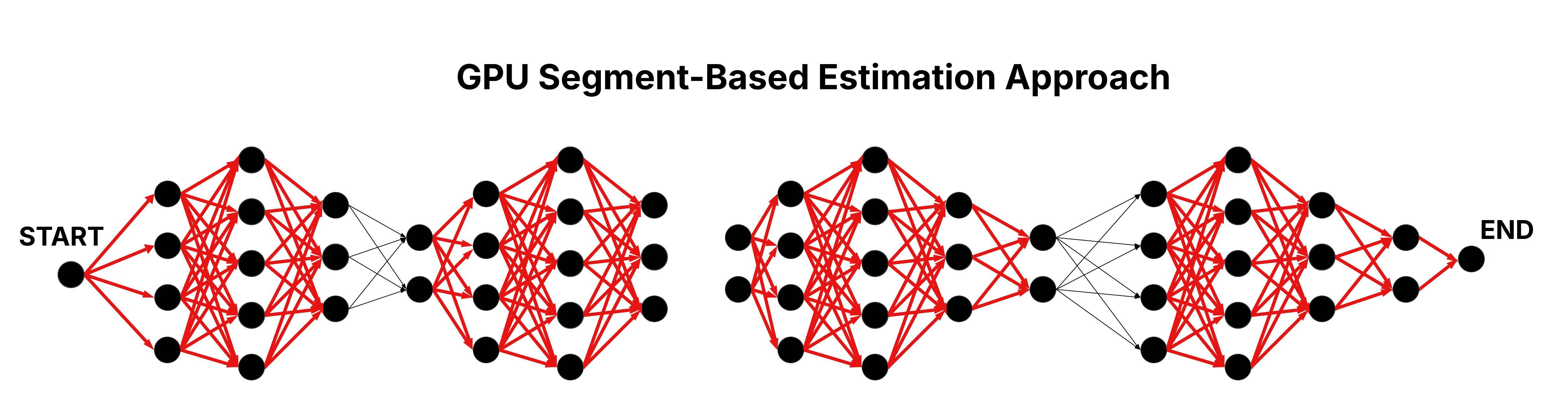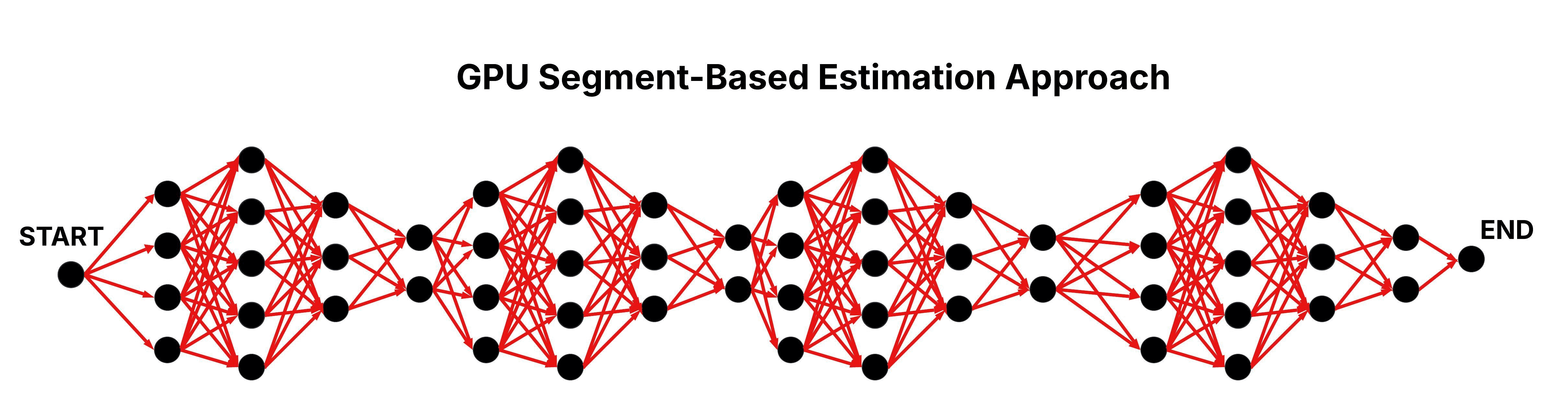
Figure: Parallel Traversal of the Layered Graph in the GPU Segment-Based Estimation Approach.
GPU Fine-Grained Approach
In the GPU Fine-Grained approach, as in the GPU Naive approach, the layered graph is processed sequentially at the layer level, but all edge computations between candidate nodes in consecutive layers are performed concurrently. Each candidate node is assigned its own thread block, and within that block, each thread computes a single edge transition. With all m × m transitions per layer computed in parallel, the time complexity is reduced to O(n).
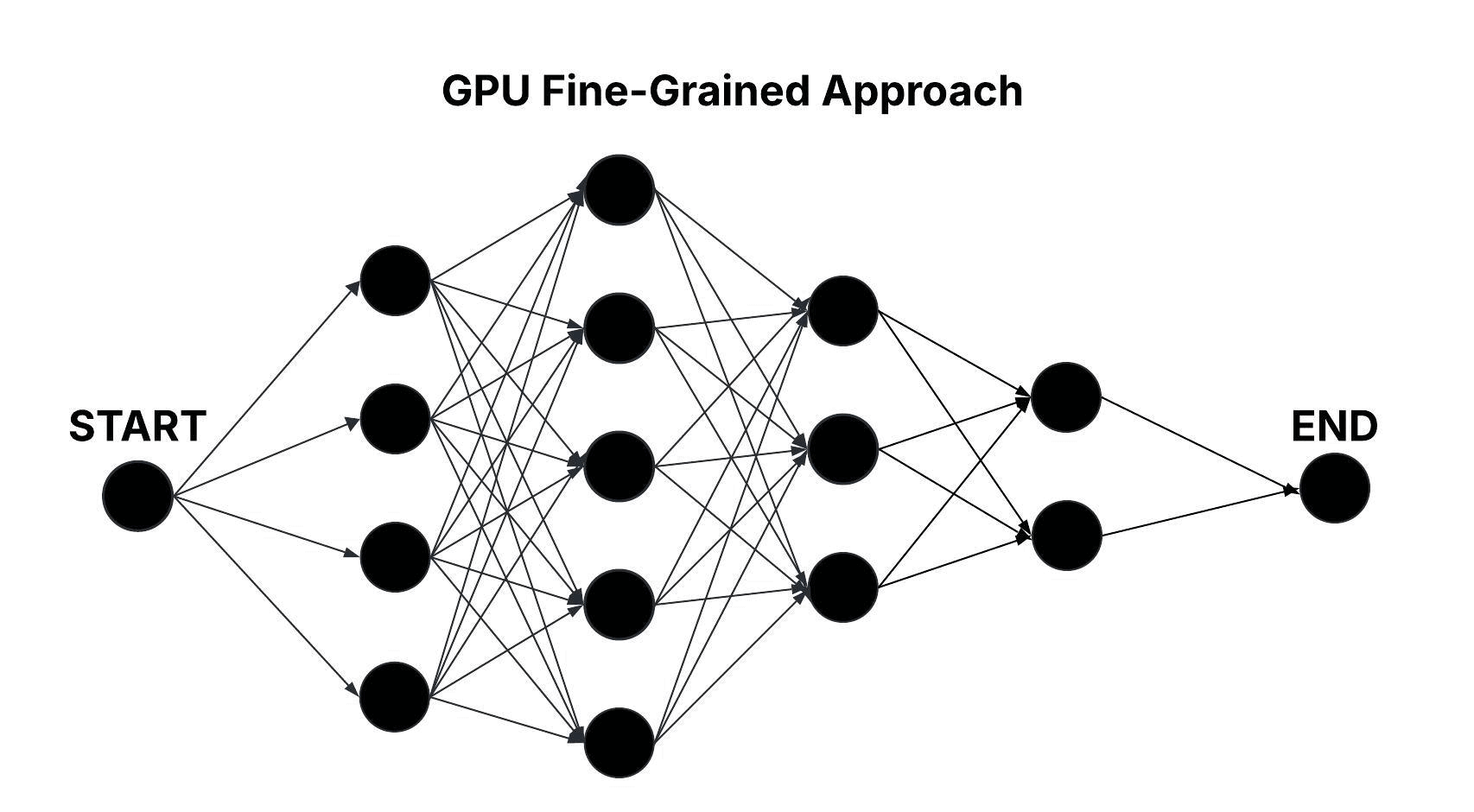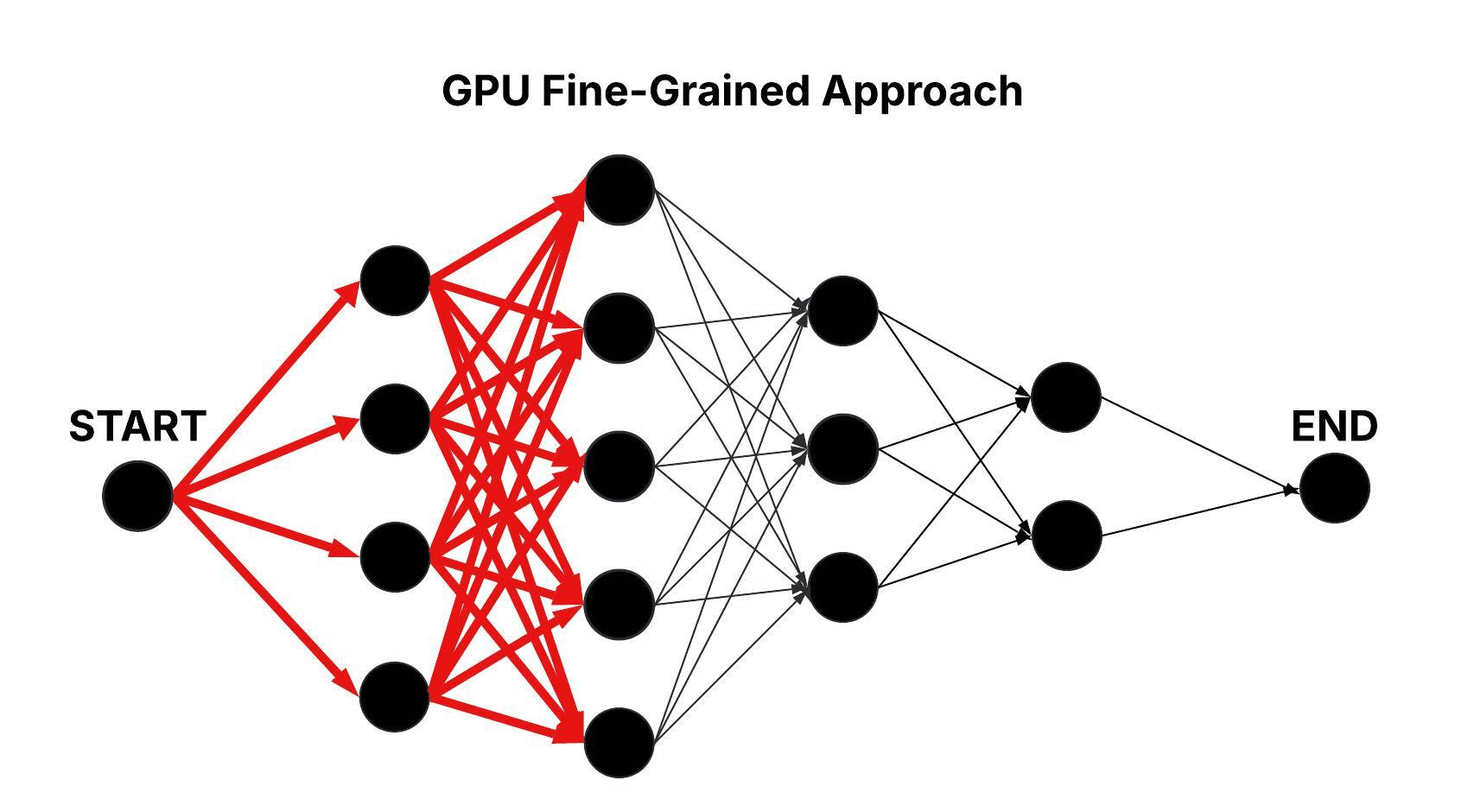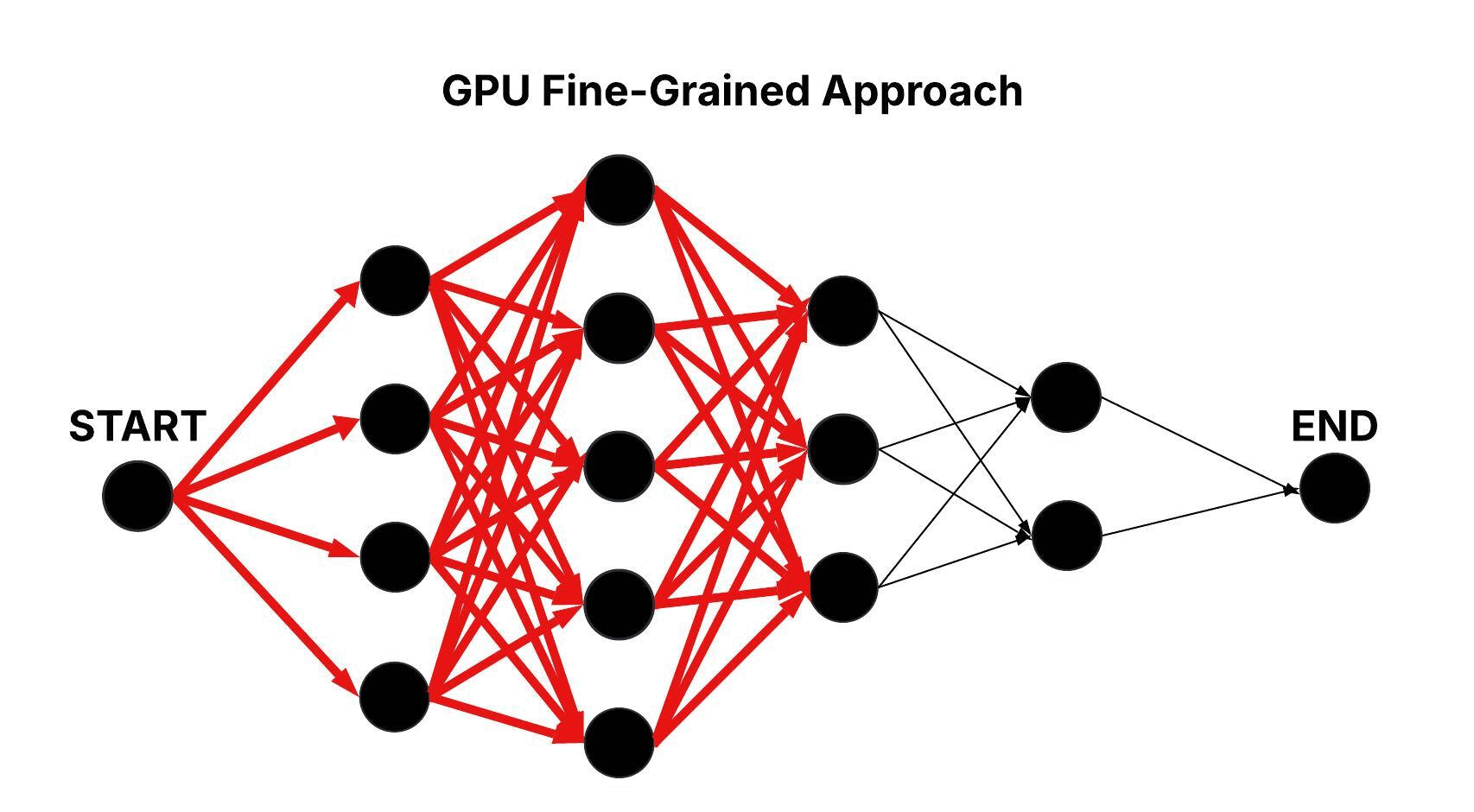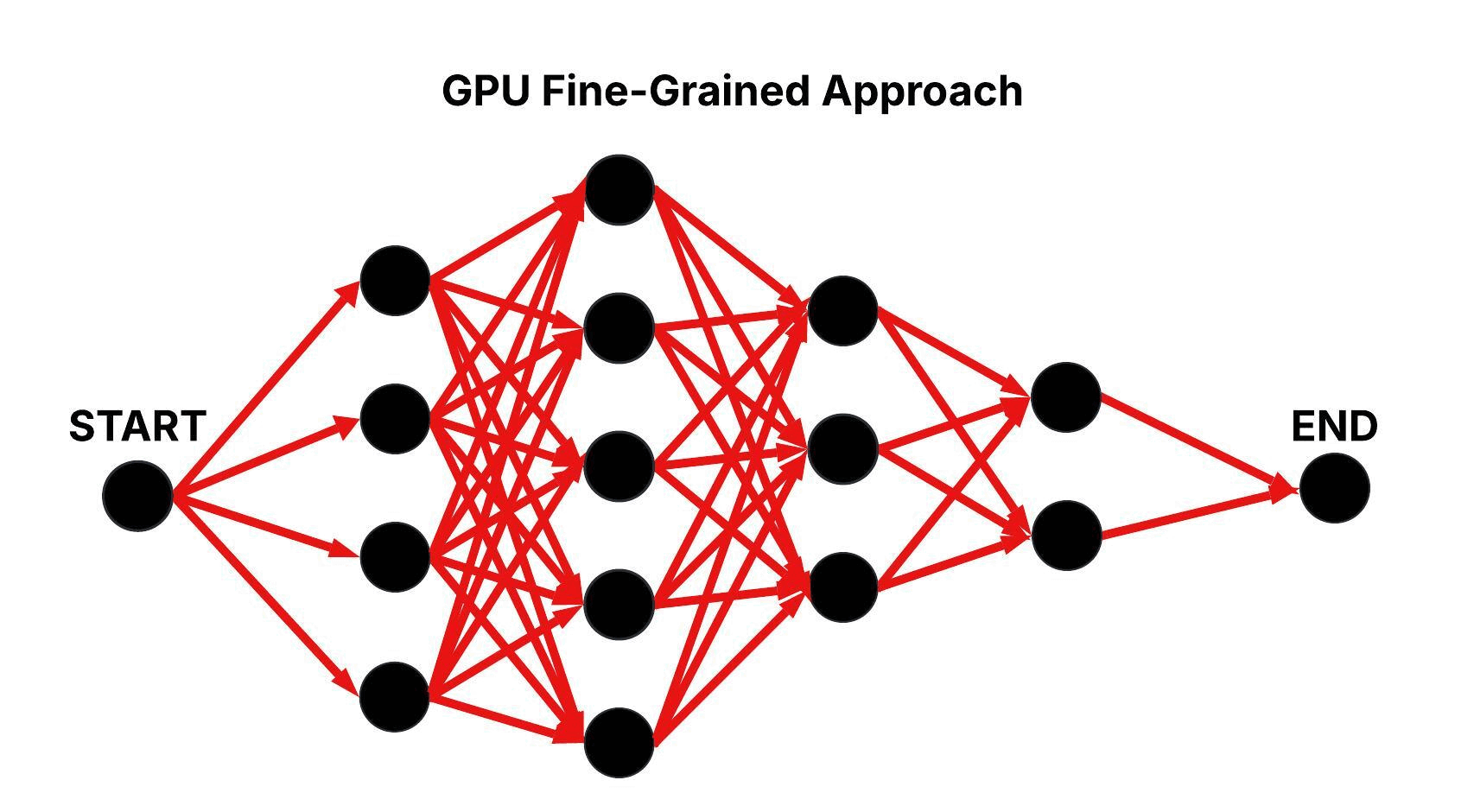
Figure: Parallel Traversal of the Layered Graph in the GPU Fine-Grained Approach.
Additionally, the GPU Fine-Grained approach introduces a parallel sorting phase using a bitonic sort algorithm. Once the cumulative weights for each edge transition are computed within a thread block, the threads immediately perform a bitonic sort to arrange these weights in descending order. In each sorting stage, every thread is assigned a pair of elements to compare and, if necessary, swap. This unique feature distinguishes the Fine-Grained approach from the Naive and Segment-Based Estimation approaches, which handle sorting iteratively.
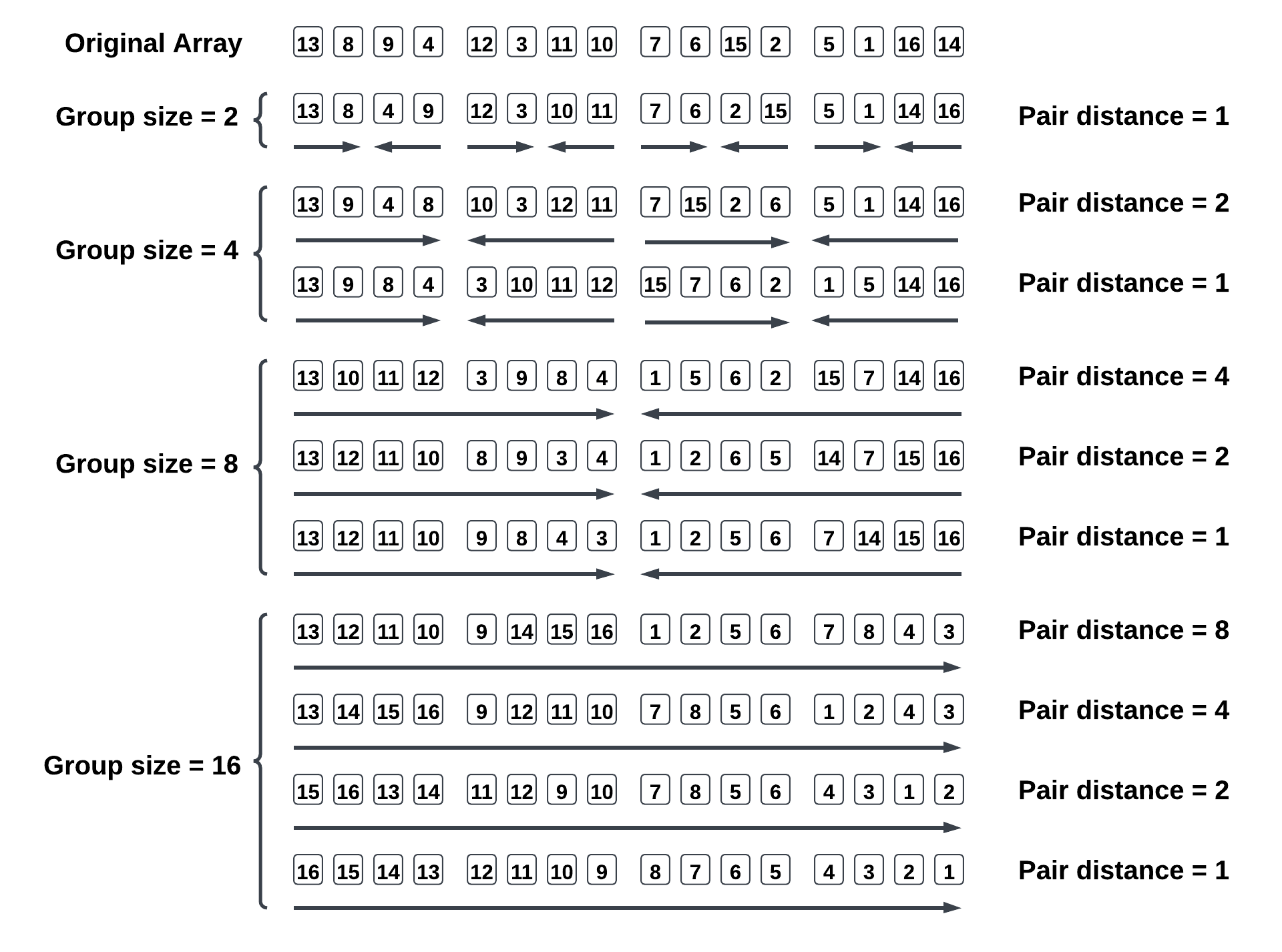
Figure: Bitonic Sort.
Status
RevDecode has been recently submitted to the USENIX Security Symposium 2025 for review. In light of the ongoing evaluation process, the source code is currently under embargo and will be released publicly once the review is complete and the work is accepted for publication.